Students will be given more than 1.5 million wrong GCSE, AS and A level grades this summer. Here are some potential solutions. Which do you prefer?

The results of this year’s school exams will be announced in a few weeks’ time. But as recently reported in the TES, Times and Telegraph, different examiners can legitimately give the same script different marks. As a consequence, of the more than 6 million grades to be awarded this August, over 1.5 million – that’s about 1 in 4 – will be wrong. But no one knows which specific grades, and to which specific candidates; nor does the appeals process right these wrongs. To me, this is a ‘bad thing’. I believe that all grades should be fully reliable.
When I speak about this, someone always says, “That’s impossible”.
No.
It is possible, and this blog identifies 22 ways to do it. None is perfect; some are harder to implement, some easier; some might work better in combination. So imagine you have total power. Which would you choose, and why? Or would you prefer to maintain the status quo? Answers, please, as comments, and if you can think of some other possibilities, please post those too.
Firstly, a few words of context. Even if marking is technically of high quality (as it is), it is necessarily ‘fuzzy’, with some subjects (such as History) being more fuzzy than others (such as Physics). Because fuzzy marks can straddle a grade boundary, an original mark and a re-mark might be on different sides of a grade boundary. That’s why grades are unreliable, as illustrated in Figure 1.
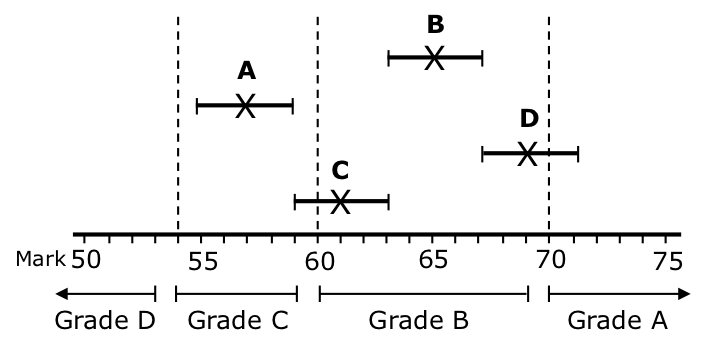
Figure 1: Fuzzy marks. Four candidates are given marks as shown by each X; other legitimate marks are indicated by the ‘whiskers’. The grades awarded to candidates A and B are reliable; those to candidates C and D are not. The length of any whisker is one possible measure of the examination subject’s fuzziness.
To award reliable grades, we need to ensure that that any original grade is confirmed by a re-mark, even though marking is fuzzy. The BIG QUESTION, of course, is “How?”. This blog suggests some answers.
The possibilities cluster, as shown by the sub-headings; several are variations on a theme. Each possibility has two elements: the first specifying how the grade is determined from the original mark; the second defining what happens when the script is re-marked as the result, for example, of an appeal. Since this is a blog, I will be brief; more detail is available here.
A quick note on the current process, against which any alternative can be compared:
- A script is marked once, with the grade determined by mapping the mark onto a grade scale.
- A re-mark is allowed only if the original mark can be shown to be incorrect as attributable to, for example, a marking error, with the re-mark determining the new grade.
Possibilities based on the current process
1. Change the policy for appeals. Allow re-marks on request, rather than requiring evidence for a marking error.
2. Double marking. In the belief that ‘two heads are better than one’, mark every script twice, and award the grade based on, say, the average, with appeals as (1).
Possibilities intended to eliminate fuzziness, with the grade determined by the given mark, and appeals as (1)
3. Re-structure exams as unambiguous multiple choice questions.
4. Tighter mark schemes, so that even essays are given the same mark by different examiners.
5. Better-trained examiners, so that examiners are all ‘of the same mind’.
6. Just one examiner, so ensuring consistency.
Possibilities that accept that fuzziness is real, but do not use a measure of fuzziness on the certificate; the grade is determined by the given mark, and appeals are as (1)
7. Review all ‘boundary straddling’ scripts before the results are published.
8. Fewer grades. The fewer the grades, the wider the grade widths, and the lower the likelihood that a grade boundary is straddled.
9. Subject-dependent grade structures. Physics is inherently less fuzzy than History, so Physics can accommodate more grades than History.
Possibilities that accept that fuzziness is real, and implicitly or explicitly use a measure of fuzziness on the candidate’s certificate
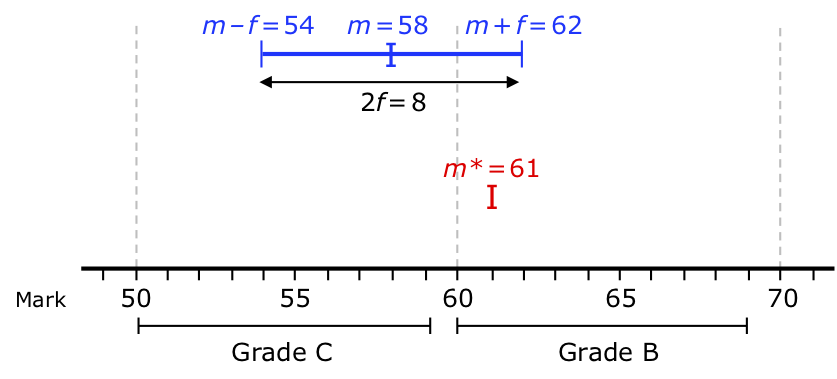
Figure 2: Grading according to m + f. A script is originally marked m = 58; the grade is determined by m + f = 62, this being grade B. There are no marking errors, and the script is re-marked m* = 61. As expected, the re-mark is within the range from m – f = 54 to m + f = 62, so confirming the original grade.
10. One grade (upper). The certificate shows one grade, determined by m + f, as illustrated in Figure 2 for an examination subject for which the fuzziness f is measured as 4 marks. If the script is re-marked m*, and if a marking error is discovered, a new grade is determined by m* + f. If no marking errors are discovered, it is to be expected that any re-mark will be different from the original mark, and within the range from m – f to m + f. Since f has been taken into account in determining the original grade, a fair policy for appeals is therefore that:
- A re-mark should be available on request (and I would argue for no fee).
- If the re-mark m* is within the range from m – f to m + f, the original grade is confirmed.
- If the re-mark m* is less than m – f or greater than m + f, a new grade is awarded based on m* + f.
By determining f statistically correctly, new grades would be awarded only very rarely – so explaining why this delivers reliable grades.
11. One grade (lower). The certificate shows one grade, determined by m – f; appeals as (10).
12. Two grades (upper). Award two grades, determined by m and m + f; appeals as (10).
13. Two grades (range). Award two grades, determined by m – f and m + f; appeals as (10).
14. Two grades (lower). Award two grades, determined by m – f and m; appeals as (10).
15. Three grades. Award three grades, determined by each of m – f, m and m + f; appeals as (10).
16 – 21. Variants of each of (10) to (15) using αf. The parameter α defines an ‘adjusted’ mark m + αf, and can take any value from – 1 to + 1. Three special cases are α = 1 (so grading according to m + f ), α = – 1 (m – f ), and α = 0 (grading according to m, as currently). The significance of α is that it determines the degree of fuzziness that is taken into account, so controlling the reliability of the awarded grades, from the same reliability as now (α = 0) to very close to 100% reliability (α = 1 or α = – 1). The policy for appeals is as (10).
22. No grade: declare the mark and the fuzziness. Solutions 10 to 21 – each of which is a particular case of the generalised m + αf concept – represent different attempts to map a fuzzy mark onto a cliff-edge grade boundary so that any marks left dangling over the edge do as little damage as possible. This solution is different: it gets rid of the cliff – the certificate shows the mark m, and also the fuzziness f for the examination subject. The policy for appeals is as (10).
None of these is perfect; all have consequences, some beneficial, some problematic. To determine the best, I believe there should be an independently-led study to identify all the possibilities (including maintaining the status quo), and to evaluate each wisely.
That said, in my opinion, possibilities 2, 3, 4, 5 and 6 are non-starters; I include them for completeness. I consider the best to be 22, with the certificate showing not a grade, but the mark m and also the measure f of the examination subject’s fuzziness. If grades must be maintained, for GCSE, AS and A level, I choose 10 (grades based on m + f), for that delivers reliability as well as assuring that no candidates are denied opportunities they might deserve. But for VQs, T levels, professional qualifications and the driving test, my vote goes to 11 (m – f ) – I find it reassuring that plumbers, bricklayers, brain surgeons, and all those other drivers, really are qualified.
What do you think?
And if you believe that having reliable grades matters, please click here…


Comments
Richard says:
Really interesting article and some great ideas. Number 7 is similar to how we internally marked functional skills exams (Although this was only pass/fail). Anyone just under the grade boundary was remarked by a line manager. Then a sample (and all boundary cases) were sent off for external verification.
I’m in favour of 7 and/or 10 when it comes to gcse/a-levels. I don’t think we should replace grades with scores as it may become confusing to interpret between subjects and years, especially for those outside education.
Reply
Metcalfe Mike says:
22 would be my preference if I were choosing applicants based on their qualifications
My worry is that a great number of my colleagues in education do not understand simple statistics as evidenced by Senior Leaders in schools looking at data points for individual students with no reference to fuzziness
Could it; Would it lead to a better understanding of stats in the general populace?
Reply
Andrew B says:
I would argue that the main purpose of grades is to act as a comparative measure, and decreasing fuzziness is the only way to achieve that objectively more fairly.
Otherwise pupils will (sensibly) continue to be compared either by their “m” mark.
Ignoring appeals for a second, all that method 10 involves is decreasing all the grade boundaries by “f” – nothing more.
The only approaches that even start to solve the problem of one pupil scoring 1 mark less than another pupil due to fuzziness and getting a lower grade as a result are the ones that don’t give grades or give less grades overall (or that reduce fuzziness).
The appeals process will never be free, and will therefore only consolidate the advantage of wealthy pupils or those from families who know how best the game the system.
There is NO system that can take the same papers and marking policy as an input and magically output more accurate grades. The only option is to aim to reduce fuzziness.
Reply
Dennis Sherwood says:
Hi Andrew. You’re right. On two scores.
Firstly, when two different examiners can give the same script two different, but legitimate, marks, then it is indeed impossible to deliver accurate grades. That’s because ‘accurate’ requires a definition of ‘right’ – and if there is no single ‘right’ mark, there can be no single ‘right’ grade (subject to the note* below).
That’s why this blog , and its predecessors, all refer to ‘reliable’ grades: a grade is ‘reliable’ when an originally-awarded grade is always confirmed by a re-mark.
‘Reliable’ is subtly, but significantly, different from ‘accurate’, and although grades can never be accurate, they can be reliable – see, for example, pages 49 to 56 of https://docs.wixstatic.com/ugd/7c5491_cf799488bf8b4bc5b9887673794eac09.pdf.
Secondly, you’re also right that “ignoring appeals”, the effect of f is to shift the grade boundaries. That’s true (but it isn’t grade inflation, but that’s another story…). But appeals can’t be ignored, for it is an appeal that discovers what happens when a script is re-marked. And it is that re-mark that is the essence of reliability. So “nothing more” is only half the story.
*There is one instance when there is prior knowledge of the ‘right’ mark. That’s when the ‘right’ mark is defined as ‘that given by a senior examiner’ – as is the case in all Ofqual’s research. If this definition of ‘right’ is accepted, then grades can be accurate only if all examiners always give exactly the same mark as the senior examiner. In the real world, this does not happen, so, by Ofqual’s definition, any other mark is necessarily ‘wrong’. Once again, accurate grades are impossible. But reliability is possible – if the policy for determining the grade from the original mark is any of my numbers 10 to 22.
Reply
Dennis Sherwood says:
I’ve just been listening to ‘The Public Philosopher’ (August 26, https://www.bbc.co.uk/sounds/play/m0007ws1), in which Michael Sandel posed the question “How would you feel if your exam were marked not by a human examiner, but by a very good AI algorithm?”.
A significant majority of his audience voted for the human examiner. I wonder.
As a powerfully able philosopher, Professor Sandel knows he is asking a false question. For the fact is that algorithms are being used now: every examiner is using a set of ‘rules’ – a mental algorithm – to make their judgements of good and bad, clear and muddled, right and wrong. The BIG PROBLEM of course is that different examiners are using different algorithms, algorithms that are not explicitly defined, algorithms that might change over time, algorithms that might change with the examiner’s mood.
As a consequence, different examiners can – and do – award the same script different marks, resulting in fuzzy marks and unreliable grades.
A (good) AI algorithm solves that. The same algorithm would be used in the same way for all scripts. Marking would be consistent, fuzziness would be minimised (if not eliminated), grades would be reliable, and – most importantly – all students would be treated fairly.
So solution 23 is to use AI for marking.
Thank you, Professor Sandel!
Reply
Peter Twining says:
Interesting article.
Minor point – No6 is flawed – I am pretty sure that individual markers are not reliable (based on my own personal experience!).
More importantly – Fixing a flaw in a fundamentally broken system isn’t going to stop the system being fundamentally flawed.
Exams fail to meet the characteristics of effective summative assessment https://halfbaked.education/characteristics-of-effective-summative-assessment/
Reply
Dennis Sherwood says:
Peter – thank you, indeed so; and no 6 is not the only flawed possibility, some much more so than others!
Many people, though, hold entrenched positions, of which “maintain the status quo” is particularly prevalent. Which is why I strongly believe that an independent study should be commissioned to identify all the possibilities, and to evaluate them wisely and fairly – independent because I don’t trust Ofqual… (see, for example, https://committees.parliament.uk/writtenevidence/12402/pdf/).
And your ‘bigger picture’ point is true too – there is much that is wrong in the way young people are ‘assessed’. That said, the unreliability of exam grades is especially disturbing: if exams are to be used, the least that can be expected is that the resulting grades are fully reliable and trustworthy.
Which they are not.
And given that it is easy to make them reliable and trustworthy, that would be a good thing to do. Agreed, it doesn’t solve the ‘big problem’. But it does make the world a little bit better…
Reply
Peter Twining says:
The best strategy for bringing about change is a real dilemma – I toggle between radical change (start from scratch – as in http://www.schome.ac.uk) or ‘tweaking’ the existing system (which is more the approach I take in http://edfutures.net). Ultimately I believe that unless we change the (summative) assessment and accountability systems nothing else will change (curriculum and pedagogy follow summative assessment) and I’m rather taken with Christensen et al.’s (2008) disruptive change model (see https://halfbaked.education/radical-change-strategy/)
Reply
Add comment