CAGs rule OK
Dennis Sherwood has been tracking this year’s ‘exam’ round for HEPI. Here, he responds to the latest announcements – or u-turn – on using Centre-Assessment Grades.
Good news!
So now we know. After all the anguish since the A-level results were announced on 13 August, teachers’ Centre Assessment Grades (CAGs) will be the grades awarded to students across all four UK home nations. It is the algorithm that is for the shredder, not the teachers’ grades.
This is good news.
I don’t have any robust numbers, but my expectation is that very many, close to nearly all, students will have been awarded the grades they deserve. There will be some lucky students, whose teachers deliberately ‘gamed the system’ and intentionally submitted over-the-top grades, and who have got away with it. But, despite all the blaming of ‘over-optimistic teachers’, I believe that the known over-bidding of CAGs, as compared to the now-discredited statistical standardisation model, is much more likely to be a result of nothing more than the need to round fractions to whole numbers, and flaws in the statistical model itself, of which more shortly. So my guess is that the number of students who have benefited from their teachers’ lack of integrity is small.
There may be some teachers who acted conscientiously and with great diligence to follow the ‘rules’ – as far as they were specified – and who are now thinking, ‘Well. That will teach me to be honest! If I’d have gamed the system, my students would all have been awarded higher grades’. I understand that; but, in my view, teachers who behaved with integrity did the right thing.
Most unfortunate, though, are the teachers who followed the rules, but because there was no opportunity to submit and explain outliers, felt forced to constrain their submissions, down-grading able students. Regrettably, students caught in this trap cannot, I believe, appeal. They are the victims of this year’s vicious process, and I grieve. I do hope there are not too many of them, but ‘too many’ has no meaning to the individual who suffers the damage.
This year’s grades are the fairest ever
Overall, however, I believe that the prediction I made in my very first blog in this long saga has come true.
On 21 March 2020, the day after Gavin Williamson announced this year’s exams would be cancelled, I floated the possibility that the year’s results, being largely determined by teachers, could well be more reliable than those determined by exams, if only because exams are so unreliable – on average across all subjects, about 1 grade in 4 has been wrong for years. Since exams are only 75% reliable, that sets a very low bar. Even better was Ofqual’s announcement that teachers were being asked to submit student rank orders as well as the CAGs. There was then and there is now no doubt in my mind that a conscientious teacher will do a much better job at determining a fair rank order than the fuzzy-mark-lottery of a rank order determined by an exam.
So now we know that the teachers’ grades have ‘won’, I have absolutely no doubt that this year’s grades are the fairest ever, and certainly better than the 25%-of-grades-are-wrong that we have all suffered – largely unknowingly – for the last several years. And, yes, some people will have been lucky as a result of gaming, and – very sadly – some will have been unlucky as a result of being on the wrong side of a grade boundary. Overall, though, this year has to be better, much better, than 75% right, 25% wrong.
What was wrong with the statistical model?
But why has the statistical model been thrown away?
Now that the details of the model have been published, and much pored over by expert statisticians, there have already been many articles, blogs and news interviews identifying any number of reasons why [this] aspect of the algorithm is not the best that might have been used, or why [that] way of estimating [whatever] number suffers from [this particular] problem. These criticisms are all very likely to be valid, but this ‘microscopic’ view misses the big picture.
The model was doomed from the outset.
As is now evident, the objective of Ofqual’s method was to predict the distribution of grades for every subject in every school in England. They had some very clever people doing this, but the objective was foolhardy, and inevitably led to the disaster we have all experienced.
To attempt to build a model that makes accurate predictions, two conditions are absolutely necessary:
- It must be possible to verify success, after the event.
- If the method of prediction is complex, there must be a way to test that method by using known historic data to ‘predict’ known historic results.
To take a trivial example, your prediction of the winner of the 3:50 at Doncaster can be verified, or not, by 3:52; a more sophisticated example is weather forecasting, for which the success of the underlying complex models can be verified, or not, when you look out of the window and see the torrents of rain, just as was forecast the day before.
Furthermore, sophisticated weather forecasting models are tested using historic data. The ‘inputs’ to the model – air pressures, temperatures, and the rest – are known for any day in the past. These can then be entered into the model for a given historic day; the model can then be run to derive a ‘forecast’ of the following day; those ‘predictions’ can then be checked against the known weather for that day, and the model deemed good, or poor, accordingly.
How might this apply to the prediction of exams?
Suppose that the model predicts three grade As for A-level Geography at Loamshire Community College. How would you determine whether this prediction is right? Or wrong? There is no ‘winning post’ as at Doncaster. There is no ‘tomorrow’ when you could see the rain through the window. And, most importantly, there is no exam. There was, and is, no way to know, ever, that the prediction was, or was not, right. So why bother to try to predict?
That’s bad enough. But the problem with testing is even worse, as described on pages 80 and 81 of Ofqual’s report, and Tables E.8 and E.9 on pages 204, 205 and 206 (really – the model’s specification document runs to 318 pages).
Briefly, the algorithm’s designers developed 11 different ‘candidate’ predictive models, and, understandably, wished to choose the best, where ‘best’ is the model that predicted a known past most accurately.
The only ‘past’ that is available, and that they were obliged to choose, is the data set used to make the (very important) estimates of the reliability of exam-based grades, as shown in Figure 12 of Ofqual’s November 2018 report Marking Consistency Metrics – An update.
This Figure is well-known in the HEPI archives, and features in my blog dated 15 January 2019 as the key evidence that, on average, 1 exam-based grade in 4 is wrong. So the benchmark being used for testing the predictive algorithm is itself wobbly.
The results of testing their algorithms against this wobbly benchmark are reported in Table E.8 for A-level and Table E.9 for GCSE. So for example, their best model for A-level Economics predicted the ‘right answer’ with a probability of about 64%; for GCSE Maths, 74%; for A-level Physics, 59%; for GCSE History, about 55%.
Here is a table that does not appear in the Ofqual report, but that I have compiled, drawing together the measurements of the reliability of exams (that’s the ‘Benchmark’ column), together with the measures of the accuracy of Ofqual’s best predictive model, for a variety of A-level and GCSE subjects:
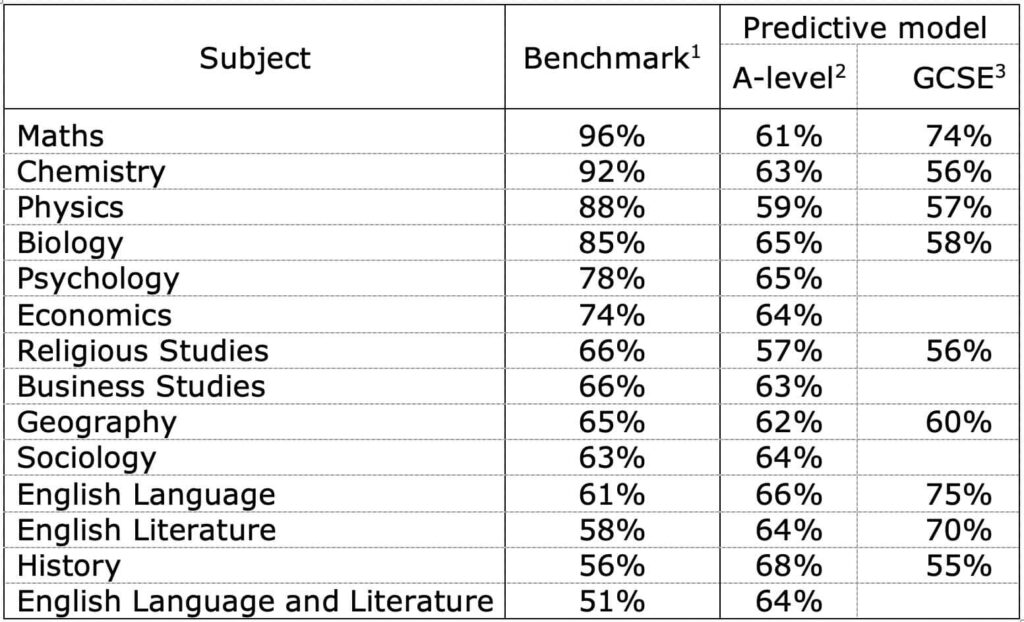
2 Ofqual model specification, Table E.8
3 Ofqual model specification, Table E.9
Look at those numbers.
How could Ofqual use a model that is only 68% accurate for A-level History, for example? And have the effrontery to use that to over-rule teacher assessments?
Their explanation is because that is not quite as bad as the 56% reliability of the exam! That is hardly a plausible excuse for History. But for Maths, which is associated with an exam accuracy of about 96%, the model achieves only 61%. So about 4 in every 10 of the ‘statistically moderated’ Maths A-level grades ‘awarded’ on 13 August were wrong!
No wonder the model has now been binned.
As a by-the-by, Tables E.8 and E.9 hold another secret. As well as showing the ‘predictive accuracy’ of the model for each subject, there is another column headed ‘accuracy within a grade’, this being the measure of the accuracy of the model in predicting the ‘right’ grade or one grade either way. These numbers, not surprisingly, are considerably higher – quite often 90% or more – than the ‘predictive accuracy’ of the ‘right’ grades alone. Is that why so many important people, fearful of referring to the low numbers of ‘predictive accuracy’ of the ‘right’ grade were so careful to use words such as ‘there is a high likelihood that the grade you will be awarded is the right grade, or one grade lower’?
The model was fatally flawed at the start.
This is not hindsight, nor does reaching this conclusion require great statistical knowledge. It is, and was, obvious to anyone who might have given the matter a moment’s thought.
The demise of Ofqual’s model has not been a failure in statistics, in handling ‘big data’, or in constructing smart algorithms. It was a catastrophic failure in decision-making.
‘The fairest possible process’
The more so in the context of a phrase that has been widely-used to excuse the use of this model, until the moment it was thrown away. How many times have you heard words such as ‘In these unprecedented times, this was the fairest possible process’?
No. Building a model attempting to predict the grade distribution of every subject in every school was not the fairest possible process.
A far better process would have been to build a very simple model to ‘sense-check’ each school’s submissions as being plausible and reasonable in the context of each school’s history – exactly as described as the second possibility in my ‘alternative history’ blog and as illustrated in the diagrams in my ‘Great CAG car crash’ blog, which was published on 12 August, the day before the A-level results were announced.
And in this context, there is still much talk of ‘over-predictions’ by ‘over-optimistic’ teachers – a euphemism, I’m sure.
I think the jury is out on that.
My ‘Great CAG car crash’ blog tables the possibility that much might be explained by rounding errors, a theme picked up in a subsequent Guardian article. And since teachers are – I think unfairly – being blamed for being ‘over-optimistic’, I believe that it is important to establish the facts, as described in the ‘Great CAG car crash’.
I therefore believe the entire data set should be handed over to the Royal Statistical Society for careful forensic analysis. Now.
The end (nearly)
Well, we’re nearly at the end. Not quite, for there are many important matters to be resolved, from unscrambling the A-level mess to sorting out university and college entrance, from the political fall out to (I hope) radically reforming exams, assessment, the curriculum and – very importantly – resolving the social disgrace of the ‘Forgotten Third’, the one-third of all GSCE English and Maths students who are condemned to ‘fail’, before they have even stepped into the exam room, this being a direct consequence of the ‘no grade inflation’ policy.
The immediate chapter, however, the chapter of awarding exam-free grades, is at an end.
Fair grades have, to a very great extent, been awarded – in my view the fairest ever.
Sense has prevailed over statistically obsessed mad scientists and deeply entrenched bureaucrats. Public pressure has won.
We are in a good place.
So let me close this series of blogs here. But before I ‘sign off’, it is my very great pleasure to thank, and acknowledge, the very many people with whom it has been a such a pleasure to share ideas, to talk, to debate, to think. So many thanks to Huy, to Rob, to George, to Mike, to Michael, to Janet, to Craig, to Tania, to everyone who has contributed lively, engaging and oh-so-intelligent thoughts, ideas and comments. My thanks to you all. (Further thanks of course to Nick and Michael at HEPI, whose speed, efficiency, wisdom, constructive suggestions and especially patience in dealing with my requests ‘to change that inverted comma in line 17, please’ have been of immense value and benefit.) And, finally, all good fortune to those students for whom doors are now open, rather than slammed shut.


Comments
Craig Feather-Moore says:
A final tour de force to conclude a series of blogs that made people of influence sit up, listen and act. Many have only focussed their attention on the grades scandal during the past week. Dennis Sherwood has been shining a light on it for months. The government U-turn yesterday was brought about by the sheer weight of public opposition. It demonstrates that people power can succeed in shaping decisions if a sufficiently strong alliance is capable of being forged across the political divide. Young people should take most of the credit for their success, aided by high profile figures like Andy Burnham and the journalism of Lewis Goodall which vividly highlighted individual injustices created by an algorithm. Robert Halfon and the Commons Education Select Committee also deserve plaudits for holding Ofqual’s feet to the fire. As a parent of a child who has been affected by this crisis, my overwhelming feeling now is one of relief after five anxious months which culminated in five truly forgettable days for us as a family. Thank you Dennis for your support and for the significant contribution you have made towards achieving a just and fair outcome for hundreds of thousands of young people.
Reply
Charlie says:
Thank you for this excellent series of blogs.
Reply
Tania says:
Well said Craig. Dennis’s article is an excellent summary of this shambles.
We can all hope that the emperor’s New clothes which swathed OFQUAL and the exams system have been revealed and people with ability to make decisions realise that it is time for a change.
Thank you Dennis.
Reply
Huy Duong says:
Hi Dennis,
I think the latest rule is that mock grades are no longer allowed in appeals, so CAGs rule.
However, I think if the school accepts that a submitted CAG is wrong and issues a new one then that might be valid ground for appeal.
Reply
Lesley CORPS says:
Hi Huy,
I am looking at avenues to challenge the CAG for my daughter who I believe is one of the unlucky ones in this whole sorry mess. On what grounds could the (STEM) college decide it is wrong – is this the bias /discrimination angle? I am pursuing an appeal, not to regain her place at Leeds, she is now going to Kent to study mathematics. It is to restore her self belief. This process has seriously undermined her self esteem, based on estimated grades of performance.
Reply
David Thomson says:
I’ve very much enjoyed this series Dennis, though I wish I hadn’t had to.
On accuracy, the RSS noted that the test on previous data was not directly comparable with the 2020 process since exam marks (rather than centre ranking) were used to rank students.
Even then, the comparison with actual grades is based on two fuzzy numbers. Even in the ‘marking consistency’ work, the true grade for a student is unknown. The score of the expert examiner is treated as such- though I can imagine that expert examiners would tend to mark more similarly than other examiners.
I thought the “mad scientists” comment was a bit harsh though. I would have expected those involved in developing the model to have worked diligently to try and deliver what they were asked to do. Clearly, some thought has gone into it. But it’s clear it could have done with some external input, especially schools sense-checking the data.
Reply
Huy Duong says:
Hi Lesley,
Some possibilities which needs to be explored further:
1. The centre did not follow the correct procedure. Eg, instead of assigning a CAG to a student based on that student’s attainment and progress then rank the students within that grade band, they might have ranked all the students in the cohort first then apply grade boundaries based on cohort-wide and/or historical data. Incorrect procedure is a ground for appeal.
2. If a teacher has a thought such as “Hm…looking at our historical data, it looks like 4 A*s would be reasonable this year”, that seems to me to constitute a bias in the assignment of CAGs against the 5th and 6th students in the rank whose attainment and progress look like A*. Bias is a ground for appeal.
It seems to me that the key for these arguments is whether the centre accepts them.
Reply
Huy Duong says:
Hi David,
It’s not good enough for Ofqual to say “We were just following orders. We did our best to be just”.
Professional ethic required Ofqual to tell Williamson that they can’t achieve the double aim of keeping grade inflation to, say, 2% without a specific level of injustice (especially with the rubbish appeal rules earlier on). Then Williamson would have been able to decide and would have to decide. Maybe that’s what happened? We don’t know, but Williamson pleads ignorance. If that’s true then Ofqual has failed in professional ethic. It has certainly failed in its duty to the public in not telling us how untrustworthy its model is until it was too late.
But even if Williamson’s ignorance is true, that still doesn’t let him off. He had duty to know, and if he didn’t know then he had to ask Ofqual. Not asking would be negligence and incompetence.
Some other questions are:
Did Williamson know about the high risk of injustice and still made Ofqual do it?
Ofqual certainly knew about the high risk of injustice but it did not disclose it to the public. Could it have done a similar thing to Williamson? Eg did it use statistics in the manner of “lies, damned lies and statistics” to blindside him? Or did it tell him clearly but he simply did not understand?
Reply
Keda Richens says:
My twin daughters’ FE colleges (separate-within London) both have classes of 30+. Both got 9’s at (Art) GCSE and A’s in assessments throughout their A level courses, and were told what they needed to do to achieve A*’s at their final assessments. Both worked equally hard and are very talented in quite different ways.
Yet one has received a final grade A (which we are happy with) and one got a C.
When we first complained about the C result the teacher said she was glad we would be appealing and would support us. Yet once we asked for the CAGs and rankings after the government U-turn it still showed a C and a ranking of 3.
Her teacher now says the centre downgraded the mark she assigned on the CAG to a C but cannot help us further as she is now in a difficult position. We have still been given no guidance from the college on how we can appeal this.
Many colleges obviously already downgraded their students rightful and deserved grades in their CAGs to fit previous or expected patterns. We are heartbroken, angry and extremely frustrated as if we can’t change this wholly unfair grading they will follow her and be detrimental to her chances throughout her life.
Reply
Huy Duong says:
Hi Keda,
It seems like Ofqual’s instruction is that the centre has to apply a moderation. Unfortunately, some centres must have applied this moderation more aggressively than others, or some cohorts had more outliers than others. So variable numbers outliers were downgraded in different cohorts. But it seems there is no redress. My son got caught in this trap, which Dennis mentioned, so he has A in maths and A* in further maths, which is much, much harder. In 2018, just 0.2% got higher grade in maths than further maths. Luckily for him, it’s just a scar as souvenir of someone else’s craziness, but the damage and hurt for other students are bigger.
Reply
Keda Richens says:
Thank you for this Dennis and Huy.
Unfortunately one of my daughters is one of the very unlucky ones who did not only get stuck on the grade boundary but was put down by 2 grades (at least!) by her overzealous college ignoring her past performance and teachers grades.
I cannot, and will not, accept that there is no redress for this though. Because as Lesley mentioned it’s so important for her self esteem and self belief.
As a straight A student who did well in her other subjects Art is still her favourite and is what she wants to pursue. Luckily her portfolio, which she put together herself during lockdown and submitted online, got her an unconditional place on her foundation at Camberwell. But going forward to a degree next year and for future jobs she will still need a strong and reflective A level grade, not a C which doesn’t do her work, talent or work ethic justice at all.
Reply
Huy Duong says:
Hi Keda,
It is definitely an injustice, and I sorry about your daughter’s situation. As far as I can see, the potential routes for redress are:
1. The school accepts that it made a mistake with her CAG, AND is able to prove that mistake to the board. Both of these steps are hard.
2. The appeal rules are changed. This will take at least a lot of pressure from the schools, but I’m not sure if the will is there. What I have learnt from this is schools tend to be compliant. It was obvious from April, even to an amateur like me, that what Ofqual was trying to do was not going to work and the risk of injustice was huge, but most schools just went along with it. With all the schools we have in the country, few spoke up.
3. Legal challenge. This is a big undertaking, especially if you lose you might have to pay the other side’s costs.
It seems the first route is the only one accessible to students and their parents.
Reply
Huy Duong says:
Ofqual told the schools that in assigning the CAGs they had to take into account “previous results in your centre in this subject – these will vary according to a number of factors, including prior attainment of the students, but our data shows that for most centres any year-on-year variation in results for a given subject is normally quite small”.
However, the “but our data shows that for most centres any year-on-year variation in results for a given subject is normally quite small” is false for A-levels. So maybe Ofqual asked the schools to assign CAGs based on a false premise? Maybe that created a bias against outliers?
Reply
PLEASE HELP ME says:
We are not in a good place! I cry myself to sleep everyday. I haven’t slept or eaten well in days. I was predicted A*AA for my university application and my CAGs given were BBC!!
I spoken with my deputy head teacher who said I can’t appeal – as there’s been no administration error or malpractice. Ofqual haven’t made an appeals process available.
I’ve LOST my place to study Biomedical Sciences at Kings College London. I feel so sick and a pit in my stomach there’s no news about students like me. The media have forgot about us and moved on kicking the dirt in our face. I’m from a single parent household- would’ve been the first to attend university and of BAME background. I can’t sleep, it hurts.
Reply
Melisa says:
We are not in a good place! I cry myself to sleep everyday. I haven’t slept or eaten well in days. I was predicted A*AA for my university application and my CAGs given were BBC!!
I spoken with my deputy head teacher who said I can’t appeal – as there’s been no administration error or malpractice. Ofqual haven’t made an appeals process available.
I’ve LOST my place to study Biomedical Sciences at Kings College London. I feel so sick and a pit in my stomach there’s no news about students like me. The media have forgot about us and moved on kicking the dirt in our face. I’m from a single parent household- would’ve been the first to attend university and of BAME background. I can’t sleep, it hurts.
Reply
Simon Kaufman says:
Huy’s questions above (18/08 17:45) go to the heart of any independent inquiry which might be held; in the event that no such inquiry is forthcoming they should be top of the list of issues to be raised by the Select Committee at the inquiry they are surely bound to mount once parliament resumes – perhaps Robert Halfon could ask Huy to act as an adviser to his committee if he cannot ask him to be an expert witness.
Turning to Keda’s concerns surely the first step would be to make an appeal within the school/college in respect of its internal processes; even then it remains almost wholly oblique as to how anyone could take this issue forward with the Exam Boards/Ofqual.
Whilst understanding the issues of self-worth/esteem Keda speaks for in respect of her daughter it is surely better to focus her energies on her upcoming FAD programme; if presumably she intends to move forward with a degree and career in Art & Design then it is her FAD outcomes, portfolio and supporting sketch books showing the evolution of her ideas which will largely determine the outcome of a future UCAS application at the vast majority of A & D courses ( and absolutely in terms of internal progression to any of the constituent colleges comprising UAL) rather than the currency – or otherwise – of her AL grades. This is not to downplay the sense of injustice she presently feels at the CAG award made to her this year but may well help Keda, her daughter and family to direct their energies most appropriately as she moves forward into the next exciting phase of her further education.
Reply
Keda Richens says:
Thanks you Huy and Simon.
Although we do agree my daughter needs to focus on her foundation for her self esteem, it still feels so wrong to just accept this injustice. Especially when we consider Melisa’s comment above, and all the others who have now lost places at Uni and don’t have a foundation route or portfolio that can help redeem them. There MUST be a way for these poor students to get their voices heard and their grades reversed to what they actually deserve.
To Melisa I say I am SO sorry. I’m not sure how we can help but I will keep fighting for you and for others in your position. We are also a single parent family, needing bursary help and although I was myself the first in my family to go to uni I did most of my studies as an adult on benefits and I understand the struggle. I got bad grades at school back in the 80’s (through deprivation and low expectations) and they did hold me back until I did a foundation and went the Art route through BA, PGCE and MA in adulthood when my life experience gave me other ‘ins’.
But this is just not an option for young people with more academic and science/maths interests. They need justice and access NOW. Best of luck to all our young people. And thank you all here for taking an interest.
Reply
Dennis Sherwood says:
Hi everyone – I’m writing this at about 6 pm on 20 August, GCSE results day: please forgive me for not having responded sooner! The good news, though, is that the discussion has a momentum of its own, and does not benefit from being slowed down by me!!!
All good points, thank you!
A couple of specifics, if I may…
Firstly to Dave: we all very much value the contribution you and your colleagues at FFT Education Datalab have provided by your excellent, and well-informed, analyses (https://ffteducationdatalab.org.uk/2020/08/gcse-and-a-level-results-2020-how-grades-have-changed-in-every-subject/). Thank you!
And I agree that not all mad people are scientists, nor all scientists mad. The combination, however, is an evil brew. And I stand by my opinion that whoever took the decision to design, build and implement “The Great Predictor”, as opposed to “A Simple Sense-Checker”, was truly mad, if not necessarily a scientist.
Lesley, Keda, Melisa… I don’t know what to say, for I fear there is no recourse against a CAG, other than on grounds of malpractice or maladministration (https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/910603/6672_-_What_to_do_if_you_have_concerns_or_questions_about_your_grades.pdf), which is very hard to prove.
And as I said in the blog (and it is my pleasure to acknowledge Huy’s drawing this particular problem to my attention), the saddest case is the student on the wrong side of a grade boundary just because the teacher felt an obligation to ‘obey the rules’ – whatever they might have been – a situation made even worse given that the ‘rules’ were so poorly defined.
For me to use the word ‘sad’ does not come anywhere close to the anguish of those who have been victims of this. But, sincerely, I don’t know what can be done about it.
So if anyone does have any suggestions – and if in particular there is a lawyer out there who might have some ideas – please let’s keep this blog going…
Reply
Melissa says:
I have an idea – hear me out.
If I’m correct in my understanding, school teachers allocated grades Using rank order which were then moderated by heads of department To give CAGs. This was then submitted to exam boards which fed this data into an algorithm.
On Monday the government made a U-turn so CAGs made by teachers were used instead of the algorithm. Or the higher of the two.
Now let’s reverse engineer this, if I’m correct CAGs are still flawed because, when teachers are assigning CAGs – they have to follow strict guidelines set by Ofqual which stipulates grades must fall in line with historical data generated by the algorithm .
So teachers were, especially in schools of low socioeconomic background and lower progression to higher education had the difficult choice of assigning a small number of spaces to top student and then ranking them according to their probability of getting that grade.
However, this is the IMPORTANT bit… if the algorithm has since been denounced, then the CAGs are flawed, since it is influenced by historical data of the school which in turn determines the number of spaces available at each grade. Made difficult by ranking
SOLUTION – do you agree?
Is to all teachers to look at all evidence of student who requests an appeal again. Teachers should be do this without restrictions on grades which can be given provided there is evidence to award it. And in doing so ranks should not be used..
MOST IMPORTANTLY, any grade that is given to a student as result of an appeal should have no implication \ effect on the rank order or grade of other students who satisfied with their grade or have accepted and hold a place at a university
Reply
Huy Duong says:
Hi Melissa,
I totally agree with you. Ofqual’s guidance to the schools included among other things two points. The first is “our data shows that for most centres any year-on-year variation in results for a given subject is normally quite small” (which is false, by the way). The second is even if the school thinks multiple students are of the same level, it must split them, otherwise the whole cohort will be rejected. That seems to be wrong for the purpose of determining a student’s attainment. I think some schools recognise that some CAGs are potentially wrong, but they also think that there is nothing they can do about it, unless they accept and can show to the boards that they have made a mistake.
Reply
Dennis Sherwood says:
Hi Melissa – thank you… yes… I wouldn’t be surprised if many teachers could well have been ‘coerced’ into ‘doing the wrong thing’, against their will, but in order to comply with what they believed the rules to be. I don’t know, though, how many ‘many’ might be.
The students who are the ‘victims’ of this will never know; the only people who do know are the teachers – and I can understand why they might not feel comfortable talking about it.
If some teachers might, that would expose the issue – which I am sure many people recognise as ‘the elephant in the room’.
I wonder, though, if there are some other elephants lurking in the room too – such as the elephant of those who gamed the system; the elephant of those who have higher grades because they benefitted from their school’s distinguished history; the elephant that arises from the stampede resulting from poking the sleeping one (if I might mix my metaphors!) such that there might be a danger that the innocent might get inadvertently get crushed.
This needs careful thinking through…
Have you spoken to any teachers?
Reply
Keda Richens says:
Hi all.
Melissa, I agree.
Dennis, my daughter emailed her teacher after receiving her first grades and said she wanted to appeal and the teacher emailed back saying she was pleased to hear that and would support her. We all assumed (I think) at that time that her grade had been altered by the algorithm.
However, once we requested and received the CAGs and ranking (3) and realised that they were the same my daughter emailed her again saying she was confused and could the teacher help. The teacher then replied saying she was sorry but the centre altered her grade and she was now in a difficult position and couldn’t help further.
I obviously don’t want to throw the teacher under the stampeding elephants, but I won’t reroute them away from her as the room needs to be broken open (if the mixed metaphors can withstand further pummelling).
Reply
Huy Duong says:
Apparently one of the school organisations sent this observation to its members,
“And there does not appear to be any intention to allow students to appeal on the grounds of their school or college having internally moderated teachers’ assessments more robustly than other schools or colleges, or for centres to resubmit their CAGs.”
So it looks like the problem is recognised, but it also looks like the schools and their organisations don’t feel there is much they can do or can do easily.
Melissa, what about your insurance choice and what about the very unsatisfactory option of taking the exams in October and taking a year out?
Reply
Dennis Sherwood says:
…thanks everyone… I am not usually a reader of the website “Conservative Home”, but this is worth a look…
https://www.conservativehome.com/platform/2020/08/john-bald-ofqual-needs-a-chairman-and-chief-regulator-who-know-about-education-if-these-cant-be-found-we-must-start-again.html
You’ll see it suggests that the hidden herd might be quite large.
I wonder if any journalists who might be reading this might be interested in a good story for Sunday?
Reply
Huy Duong says:
Hi Keda,
Your daughter can hold her self esteem high because she knows she’s good, you know she’s good and her teacher knows she’s good. If she is happy with the grade the teacher gave then I think the teacher is not at fault. Would it be worth asking the school about the process and specific details about why they downgraded her? Was there a mistake? If so you might be able to appeal.
But her situation is like my son’s in the sense that both got to where they want to go, and both learned a lot along the way, and personally I think that matters a lot more than grades.
Hi Melissa,
I’m sorry about your situation. It’s your decision if and how to fight it. If you fight, I hope you can also find a way to move forward with your life at the same time from this difficult situation to minimise the damage.
I don’t really know why Williamson is education minister. I looked him up and couldn’t see any passion for or experience in education, not even evidence of passion for his own education. Maybe I didn’t look hard enough.
Reply
Huy Duong says:
https://inews.co.uk/opinion/gcse-a-level-results-2020-downgrade-students-algorithm-quit-teaching-582789
Reply
Dennis Sherwood says:
Oh dear!
That’s exactly the awful story of “I was forced to follow orders”!
I wonder how many others there are…
Reply
Dennis Sherwood says:
Some important articles on Schools Week, about the “forced to follow orders” issue.
This one is by David Blow – a member of the panel that signed-off Ofqual’s April Consultation Document, so he was around the table in the critical period in late March and early April when the critical decisions were taken:
https://schoolsweek.co.uk/schools-that-followed-advice-to-deflate-grades-must-now-be-given-appeal-route/
And this is from the editor of Schools Week
https://schoolsweek.co.uk/government-facing-exams-challenge-over-schools-advised-to-deflate-grades/
Reply
Mark says:
I wonder if when, the majority of the data is reviewed, we see schools CAGs sticking fairly closely to historical norms with Maths and English GCSE grades as the presumption would have been at centre level that those grades would be easily-corroborated by OFQUAL SATs-based prior attainment standardisation. Other subjects will, I think, have seen more generous grading. Tough on the many disadvantaged kids in the Foundation Maths and English streams that possibly failed for the sake of centre reputation without taking even an exam
Reply
Huy Duong says:
Hi Dennis,
That is shocking. The ASCL were completely out of their depth regarding the Exceptional Arrangements, and they did not know what they were doing, but they tried to be too clever and they advised the schools to do the wrong thing, at huge risks to the students.
Does anyone have the ACSL spreadsheet mentioned in the ASCL step by step guide https://www.ascl.org.uk/ASCL/media/ASCL/Help%20and%20advice/Step-by-step-to-allocating-grades-using-ASCL-approach-v2c-D-Blow.pdf ?
That document lists the overall steps
1. From the KS2 prior attainment of those entered, use the 2019 DfE Subject Transition Matrices to calculate a “starting grade distribution” for June 2020, with its average grade and % 9-4
2. The school would state the subject VA for 2018 and 2019, giving details of the methodology / provider, and then take the average to use in the 2020 calculations. This figure is entered manually in the spreadsheet.
3. The spreadsheet then calculates what the distribution of grades would be for June 2020 which would give that specified subject VA figure (assuming uniform VA across the prior
attainment range). The average grade increases by the VA figure 2
4. The school can modify the grade distribution to fit the exact pattern of its pupils, PROVIDED that the average grade and the % 9-4 remain the same. This will maintain the necessary national consistency. Schools should consider the % 9-7.
That is preposterous. Look at step 4, with the PROVIDED in capitals. So the ASCL asked the schools to pre-Ofqualise the CAGs before submitting them. The more a school applied this pre-Ofqualisation, the less the CAGs are true CAGs. So some students are stuck with “standardised” grades even if the grade Ofqualisation has been scrapped.
I completely agree with David Blow that the government must allow appeal routes for the students/schools affected. Otherwise, we will still have residual injustice from the grade Ofqualisation.
Reply
Dennis Sherwood says:
Mark – Good thought. All the more reason to do a good forensic analysis of all the submitted data, as suggested in the “car crash” blog https://www.hepi.ac.uk/2020/08/12/the-great-cag-car-crash-what-went-wrong/.
Reply
H D DUONG says:
https://inews.co.uk/news/education/a-levels-gcses-2020-teenagers-unfairly-downgraded-schools-algorithm-599971
Reply
Huy Duong says:
https://inews.co.uk/news/education/a-levels-gcses-2020-teenagers-unfairly-downgraded-schools-algorithm-599971
Reply
Dennis Sherwood says:
Huy – thank you for drawing attention to ASCL’s document: I have not seen that before.
I think it is good that ASCL was advocating a uniform approach across their members – I have been in favour of that since my very first blog in this series of 21 March (https://www.hepi.ac.uk/2020/03/21/trusting-teachers-is-the-best-way-to-deliver-exam-results-this-summer-and-after/).
For that to work, though, not only must all ASCL schools comply in the same way, but all non-ASCL schools too – otherwise there is a real danger that one set of schools “plays the game”, but another doesn’t. That requires a lot of co-operation across the entire school and college community, which is difficult to achieve and maintain. And, from what appears to have happened for real, this was not achieved.
What I find not so good is the complexity of the guidelines, all those transition matrices and things.
As I understand it, the ‘baseline’ is the historical average (I recognise the exceptional case of the absence of history, but let’s park that for the moment). All the other stuff is an ‘adjustment’ to take account of other things, such as correlations between one educational level and another. What I just don’t know is whether the adjustment is in general as large as, or larger than the year-on-year variability of the historic data, and the effects of rounding to whole numbers. If so, then the adjustment might be worth doing. But if the inherent uncertainty in the historical numbers is greater, the effect gets lost, so why bother?
Maybe I’m just a simple fool, but simple instructions such as “be mindful of grade inflation; stay as close as you can to your simple average; and if you have any outliers (which can be defined in relation, for example, to the upper historic limit), ensure you have robust evidence (which might be transition matrices, or specific information on individual candidates), and expect that evidence to be scrutinised”.
The CAGs are then submitted and sense-checked for plausible compliance with the appropriate history; if any outliers are identified, the board goes back to the school to ensure that the evidence is good; grades are then awarded.
It seems to me that the especially fatal missing bit in the process as it took place was the denial of the ability to submit evidenced outliers, and the absence of the subsequent dialogue. That absence resulted in a”we’re right, you’re wrong” confrontation which has led to a very bad place indeed.
And given that the CAGs have now ‘won’, those who really did over-bid have got away scot-free, whilst those who played by what they believe the rules to have been have ended up being penalised. That last bit is tragic, but I really don’t know how that might sensible be resolved.
Any ideas?
Reply
Huy Duong says:
Hi Dennis,
In theory, it’s good that ASCL advocated *a* uniform approach. But what if in practice the approach they advocated is wrong?
For example, you listed three conditions for CAGs to be reliable:
“First, that teachers behave with honesty and integrity.
Secondly, that teachers are trusted.
And, thirdly, that teachers are not pressured into breaching that trust by the so-called ‘unintended consequences’ – the perverse incentives, of performance measures such as league tables.”
ASCL’s step by step guidance broke at least the third condition: it exerts some pressure that the CAG distribution should fit into a preconceived one (be that from historic data or this year’s cohort-wide data).
It might also break the second condition to some extent. By specifying what is really a statistical algorithm, it is reducing the trust put in teachers.
The premise of CAGs is “teachers know their students best”, so why didn’t the school just trust them to assign a CAG for Isaac? Why did the school have to use a statistical algorithm as well. That seems to belie the premise that the teachers know Isaac best.
The ASCL could have just advised the teachers how to assigned the CAGs to each student individually, so that the CAGs were more consistent between students. What it did might have been well intentioned, but I think it was misguided.
But I agree with you that Ofqual was the original source of that misguidance.
Reply
Huy Duong says:
Hi Dennis,
May I offer a different view?
In my view, it is not the case that ASCL gave the correct guidance, schools that followed that guidance arrived at accurate CAGs and those who did not arrived at inflated CAGs, thus gaining an unfair advantage for their students over those who played by the rules.
My view is that ASCL’s guidance were well intentioned but misguided, albeit the original source of the problem was Ofqual.
Of the schools that followed ASCL’s guidance, some students were disadvantaged by ASCL’s misguided guidance – call this group A, while some were given an advantage – call this group B.
Of the schools who did not follow ASCL’s guidance, some overbidded and gained an unfair advantage for their students – call this group C, some bidded fairly so their students were neither advantaged not disadvantaged – call this group D.
I think it’s group D, which is among schools that did not follow ASCL wrong guidance, that have the truest CAGs.
ASCL should have kept it simple and trusted the teachers, instead of diverting some of that trust into a spreadsheet and trying-to-be-clever statistical rigmarole.
Reply
Dennis Sherwood says:
Hi Huy
Thanks again… I’m sure you and I are totally in the same place, that this terrible muddle is absolutely the fault of Ofqual – or whatever malign being stood behind Ofqual with a gun saying “you do it this way… or else”.
Bodies such as ASCL, NAHT, HMC, The Sixth Form Colleges Association and the rest are then in a trap. Do they push back on Ofqual and say “that’s stupid, you can’t do that!”? Do they do nothing, and stand aside and watch the carnage evolve? Or do as best they can, trying to reconcile the irreconcilable, guiding their members as best they can to try to avoid the worst damage? And let’s remember that everyone – and that certainly includes me – believed that the CAGs would be ignored totally, and just didn’t matter: what did matter was the rank order.
As we’ve discussed before, the CAGs were in principle unnecessary – except, as was ‘discovered’ at the last moment, for small cohorts.
Imagine what would have happened if Ofqual had not asked for the CAGs – and just fudged the small cohort issue behind the scenes.
On those two Thursdays, students would have been informed of their grades, some being happy and some not. Just like every other year. The grade awarded is the grade awarded, and that’s that. There are no others, no comparisons. And even if I want a “second opinion”, that is denied as a result of the 2016 ‘reform’ of the rules for appeals which, deliberately, made it harder to appeal (https://www.hepi.ac.uk/2020/08/08/weekend-reading-something-important-is-missing-from-ofquals-2020-21-corporate-plan/).
But this year, things have been different. AS A RESULT OF OFQUAL’S OWN FOLLY, they created a ‘parallel universe of second opinions’ – there’s the ‘award’, and the CAG. I can compare them. They’re different. Why? What’s going on? At which point Gavin Williamson introduced a third parallel universe, the mocks. And others notice a fourth, UCAS predicted grades.
What’s happening? Why are there FOUR different measures of ostensibly the same thing?
The end result – and we’re not quite there yet – is a total discrediting of the whole rotten system. Great. Let it rot.
We need something much better, much more reliable, and much more fair. And not just for the brightest. For everyone – especially ‘The Forgotten Third’ (https://www.ascl.org.uk/Our-view/Campaigns/The-Forgotten-Third).
Reply
Huy Duong says:
Hi Dennis,
I expected teachers, heads of department, school heads, inter-school organisations, and even Ofqual itself to question up the hierarchy, ultimately to Williamson.
There is an element that if your superior asks you to do something that might wrong someone, you have to tell them, and that your superior has to take your concern seriously.
There must have been teachers who said to their heads of department, “I really think Anna, Ben, Cathy and David deserve A*, but I’m worried whether this process will give that to them. Our distribution curve says they are A, which seems wrong. And even if we submit A* for them, going by our past records, the boards are likely to moderate them to A as well.”
Did such messages get more and more ignored the further up the hierarchy they went? Did the schools think that it would work? Or did questions just crashed into the wall “We are refining the details of the model” that Ofqual had put up? How did Ofqual manage to silent virtually all the schools in the country and their organisations?
Why weren’t more MPs concerned about the problems?
Reply
Dennis Sherwood says:
Hello again Huy – yes, we are indeed in the same place, totally.
And let me just add two further questions:
“It has been known since the 2005 AQA paper that exam grades are unreliable.(https://research.aqa.org.uk/research-library/review-literature-marking-reliability).
Why has no one cared?
Why has no one done anything to fix this?”
Especially given that the lead author of that paper is Ofqual’s Director for Strategy, Risk and Research, Dr Michelle Meadows.
Maybe one good outcome of all this mess might be to fix this, and ensure that all future assessments are, as required by Section 22 of the Education Act 2011, “reliable indications of knowledge, skills and understanding” (https://www.legislation.gov.uk/ukpga/2011/21/section/22)
Reply
Huy Duong says:
Dear All,
As you know, the fundamental premise for CAGs is that teachers know their students best. The logical extension of that is students cannot appeal against CAGs except in case of admin errors, because there is no higher authority that can overrule teachers, who know best.
But what if some CAGs are wrong? Specifically, what if they are wrong because they were assigned in a way that violated the premise that teachers know best? If that premise is violated, arguably CAGs are no longer valid and nor is the premise that there is no higher authority that can overrule them.
Consider this scenario, which must have happened countless times:
The teacher says that Anna, Ben, Cathy and David are all A* and that there is hardly any difference between Cathy and David. She then ranks them 1, 2, 3, 3, respectively. That is her professional judgement, teachers know best.
But Ofqual and the school say, “Ties are not allowed”, so the teacher is asked to split a few hairs, and ranks them 1, 2, 3, 4. The school then uses some data other than David’s own data and draws the grade boundary between 3 and 4. In effects, it has overruled or coerced the teacher to assign A to David. That constitutes a violation of the premise that teachers know their students best.
I would say that that violation means that the CAGs affected are no longer valid, and the rule that you can’t appeal against them is no longer valid either.
Reply
Mini says:
Hello everyone,My son has received a CAG of B in Further Maths at A level.He was predicted an A ( A* A* A* A – for 4 A levels ) for this for the UCAS predictions at start of 6th form .In Nov 2019 in the 2nd year of 6th form he was diagnosed with Dyslexia, and in Jan 2020 he dropped an A level subject ( predicted A*, but not neccessary for his Uni course)to reduce his ‘mental load’ whilst coming to terms with the dyslexia. His CAG was A* A* B . Ofqual had given him A* A*C – the shock of this on results day, with the realization later on after CAG were revealed, that his own school had marked him down – most likely in anticipation of Ofqual downgrading and/or to fit into some previous year trends , leaving him failing to fulfill the conditions of both his firm and insurance notwithstanding the 2A* s ! When he was doing 4 A levels his predicted grades were higher in FM than the CAG calculated for 3 A level subjects, How is that possible? He is very upset and feels betrayed by his own teachers who should’ve given him the grade he was expected to get at exam/ or that he deserved , rather than a grade to fit into the previous years results trends. Ofqual may or may not have downgraded it but that is irrelevant now anyways.He is the only BAME child in the Further Maths set. This is at a private school in England. We wouldn’t know whether they would be following ASCL guidance etc?He was never advised by any teachers that he should not be applying to universities or courses needing A in Further Maths for admission. We have requested information about what evidence they have used to give a B and await a reply. Although he now has a place at Uni , the whole experience has left him so low and upset and angry. How can it be right that he cannot appeal against this and he wants us to get legal advice on this. Where would we even start!? Any advise would be helpful.
Reply
Gary says:
Dennis et al
Really interesting discussion. Came here like many feeling a little aggrieved around the current fiasco but have had my eyes opened to some much bigger issues. Good luck in targeting some much needed change!
After firing in a “soft initial appeal note” we received feedback from our school head which I thought was surprisingly candid and might be of interest. I understand the current appeals position (“NO!”) but would be very interested as to your thoughts on the validity of the approach taken and where this might sit on the [mal-…..] spectrum.
“The model used to determine the Centre Assessed Grade (CAG) is as follows:
GCSE (Y11)
The ranking is a total score made up of the following: Y10 CWG average, Y11 CWG average, Y10 mock and Y11 mock. CWGs have been used as they are based on performance. Two thirds of the ranking score comes from Y11 work (CWG and mock) as it is assumed that students are more likely working at their potential at this time assessments that are more likely to be representative of their final exams.
This model was applied to all individuals and all subjects to allow equitability for all students.”
I feel a little close to objectively comment on this approach (I have plenty of thoughts) but would very much welcome opinions?
In our particular instance we have a bright but slightly lazy/economic son (quite a large group!), but one who had really got his head down from the very start of YR11 and was getting great results, projections and teacher feedback. The Yr 10 year exams were an attainment low point in his whole school life but fell directly after a term time French exchange (clearly school valued the exams!) and then half term sports team trip and so were always approached as not being as critical “as long as you work really hard through YR 11”. Consequently most grades are probably one lower than might reasonably have been expected and with two subjects (one key and being taken for A level) being two down and completely out of line with any sensible assessment, teacher feedback and quite a shock. With one of the latter we made a direct comparison with a friend who is pretty much identically able – so they tell us. Under every metric referenced above and under TPGs they were identical, apart from the YR 10 exam where there was quite a gap. The other lad was awarded two grades higher – so one snook over a boundary and the other snook under another boundary. The post YR 11 mock teacher feedback had never suggested he would be getting the grade awarded but was very much already on track to do very well.
Does the grading really represent the teacher’s assessment of likely grade?
How can the head of centre sign off as “Honestly and fairly represented what the student would have been most likely to have achieve”?
Gary
Reply
Mark says:
Hi Dennis,
Just jumping back in here to say I have written to my son’s school asking them to clarify if, as a school, they adopted the ASCL approach in GCSE Maths. (I actually know they did since Stage Seven of their CAG approach states “Moderation of grades by SLT using national indicators and understanding of past school performance at subject level” (AKA pre-OFQUAL standardisation)) In this school, on average 25% of students don’t pass Maths. It seems to me that whatever the individual students CAGs were at Stage One of that same process when teachers updated the SIMs mark sheets, by the time Stage 7 had been completed, 25% of students in the rank order had been issued 3 or below simply to ensure “… the % 9-4 remain the same [to]… maintain the necessary national consistency.” If they confirm this is the case I will ask them to appeal to OFQUAL to have the original unmoderated CAGS (so-called Stage 1 CAGs) reinstated to bring the school in line with other settings (Independent Schools, Free Schools etc, who will not have applied the ASCL approach due to lack of prior performance data.) OFQUAL’s appeals process seems to allow this when it states “In line with the direction given to us by the Secretary of State for Education, a centre may appeal to the exam board if it believes the centre itself *made an error when submitting a centre assessment grade or rank order information* or if it believes an exam board made a mistake when calculating, assigning or communicating a grade. We expect that any mistakes will be quickly found and corrected.” The mistake in this case was submitting standardised CAGS which unfairly penalised borderline 3/4 candidates compared to centres where pre or un-standardised CAGS were submitted instead. I’ll let you know how it goes !
Reply
Dennis Sherwood says:
Hi Mini – there are now an increasing number of stories like yours coming to light, as you will see from Mark’s post.
In my view, schools were placed by Ofqual in a very difficult position: on the one hand, to do the best for their students; on the other, being, in their view, feeling obliged to comply with Ofqual’s ‘hints’ about a strict imposition of a policy of “no grade inflation”.
Schools that felt ‘coerced’ in this way will, undoubtedly, have felt that the grade distributions were rationed, with only [this number] of [this grade] ‘available’, with the consequence that some students were allocated CAGs a grade lower than they might truly have merited.
I, personally, do not blame the schools for this: they acted with integrity, seeking to comply with the rules as they understood them, and as a result seeking to avoid the possibility that Ofqual might over-rule their CAGs downwards – as indeed happened for 40% of A level grades, and an unknown – probably at least similar – percentage of GCSE grades, had Ofqual not reverted to CAGs at the last minute.
This too has caused significant problems as you know well. But the key question is what to do.
This is becoming a matter of increasing public concern, as reported in Schools Week (https://schoolsweek.co.uk/government-facing-exams-challenge-over-schools-advised-to-deflate-grades/): the individual mentioned, David Blow, is an ‘insider’, having been on Ofqual’s advisory panel, and so someone who can exert significant influence; also, this petition is just getting under way (https://www.change.org/p/uk-parliament-allow-the-right-for-students-to-individually-appeal-their-centre-assessed-grades-cags?utm_content=cl_sharecopy_24236229_en-GB%3A4&recruiter=88827808&recruited_by_id=5b596380-978b-11e3-a994-71b2d502d776&utm_source=share_petition&utm_medium=copylink&utm_campaign=psf_combo_share_initial&utm_term=share_petition).
My personal view – and that’s exactly what it is – is to adopt a strategy of aligning with your school, not fighting against the school: the school has been a victim of this too. So an approach to the school to explore how the school, yourselves and I’m sure many others too, might have a voice is, in my opinion, a good thing to do.
For it is my opinion that the entire blame lies at Ofqual’s door. Their ‘Guidance’ document (https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/908368/Summer_2020_grades_for_GCSE_AS_and_A_level_110820.pdf) is vague, and give contradictory and conflicting signals. Conscientious schools did the best they could under the circumstances, and so my opinion is that the more that schools, students, parents and carers can combine together to exert pressure, through the press, through the Robert Halfon’s Education Select Committee (https://committees.parliament.uk/committee/203/education-committee/membership/), the more likely it is that the matter will be resolved fairly.
That’s only my opinion; others may differ; but in the end, it is each individual’s fair grade that matters.
I hope that is helpful.
Reply
Huy Duong says:
Dear All,
I think conceptually there are 2 different types of CAGs.
The first is individual based CAGs, where a teacher considers at an individual student and says “According to my professional judgement, she is most likely to achieve A had exam gone ahead”. To me, these are CAGs that are based on the premise that “teachers know their student best”, which is also the premise for students not being able to appeal against them.
The second type of CAGs are the ones made under duress, where the schools came up with a n a priory grade distribution (eg calculated from this cohort’s prior attainment and other statistics, and/or historical performance) and gave the teacher an expectation that this year’s CAGs should be similar to that profile. To me, this is a genetic modification, a compromise , a corruption of the principles that underpin CAGs. I think schools should accept that this type of CAGs are potentially wrong, and should look into appeals with integrity, honesty and care.
So I would:
1) Ask the school to describe the approach it used for arriving at your/your child’s CAGs. If it used a procedure similar to what the ACSL suggested, try to appeal on the ground of incorrect procedure and incorrect data.
2) Make a GDPR request for all the personal data relating to the assignment of the CAG you want to appeal. Eg, did your teacher originally predict an A, but then the school excelised it into a B?
3) For state schools, make an FOI request, for the anonymised mock and assesment scores for all of the students in the grade band above your your child’s CAG. With this, you will be able to see if it is reasonable for the school to say that you/your child truly deserve the lower grade. Private schools are not covered by FOI, but in the interest of transparency, they should tell you.
Reply
Mark says:
Hi Huy,
Thanks for the response. That all seems very clear. So far the response I have back from the schools was “Teachers did have access to KS2 data but this did not impact their decisions. Grades were based on trial exam grades, Listening and speaking trials, any other teacher assessments throughout Y10/11, Mini mocks in English, any practical NEA tasks completed if applicable.” – this I believe is the the raw CAG as. – had they applied the ACSL pre-OFQUAL standardisation, this would DEFINITELY have used KS2 data. I have asked the school therefore to clarify their approach. I will get my son to make a SAR for the grade info as he is of age and I will submit an FOI as it is indeed a state school. I agree about the pre-standardisation being a mutation as Independents and Free schools would have lacked that data so their CAGs would be much more teacher-based. It is frustrating to to read the results described as “unmoderated CAGs” when the ACSL mandated standardisation with Dept Heads requested to sign that this was accurate. Everything the algorithm was pulled to avoid had already occurred before the CAGs and rank order left the schools that complied with the step-by-step.
Reply
Keda says:
Hi everyone.
First of all thank you all so much for your careful consideration of all these matters. It is really useful, and I’m so glad I found this original post!
I had to take the weekend off as it was getting too angry! But now feel a little better.
Huy, I will do as you suggested in asking for Gdpr and FOI requests. And I’ll let you know of any developments. Looking forward to seeing what else comes up.
Best of luck.
Reply
Mark says:
Hi All,
Much has been made of the FTTEducationDataLab report into CAGs at the beginning of June (https://ffteducationdatalab.org.uk/2020/06/gcse-results-2020-a-look-at-the-grades-proposed-by-schools/) This was basically the tipping point from using CAGs towards statistical predications to generate grades. 2400 schools participated, uploading their “raw” CAGs into the Aspire system which uses an ASP concession to access the DoE’s NPD. There is a vimeo of the process here (https://vimeo.com/413936181) but it is worth noting that – in the absence of any clear guidance on how to implement the OFTQUAL and ASCL centre level guidance, many schools will have fallen back on this free service. In exchange for providing a CSV data-set of candidates and their predicted grades in all subjects, schools got back an FTT report which told them how far away they were from the “expected” grades for their cohort. This later became the shrill headlines about “Teachers over-estimating CAGs” and “Rampant grade inflation” when FTT released the data-analysis, but in reality some or all of those schools (over half of State Schools submitted their “raw” CAGs) will have used the report they received to standardise their final submitted CAGs as it moderated grades based on the same criteria as both OFQUAL and ASCL had suggested (KS2 Prior Attainment, last years results, historic cohort data). Fast forward to August and the reversion from the OFQUAL algorithm to “original” CAGs and half of the state school cohort were actually reverting to CAGs that had already been subject to FTT GCSE Statistical Subject Moderation, not the “raw” CAGs that all other settings would have reverted to. Anyone with an interest in students on the critical 3/4 border who ended up failing their exams might be well advised to find out if their school subscribes to Aspire and participated in the FTT GCSE Statistical Subject Moderation. If they did, submit a SAR under GDPR to request the Aspire data held about them, a copy of the FTT report and the pre-FTT “raw” CAGs that were submitted to the FTT algorithm. Any school that amended its “raw” CAGs as a result of statistical moderation via the FTT process will have unwittingly placed its students at a disadvantage by pre-standardising their CAGs – an issue that could affect up to 50% of the state cohort. Although FTT made it clear there was no obligation to implement the recommendations in the reports, in the absence of any other way to conform with both the OFQUAL and ASCL Comparable outcomes edicts, many school most likely did. With the result that fail grades for many borderline students who might have been shown leniency in original “raw” CAGs became inevitable post the FTT exercise.
Reply
Huy Duong says:
Thank you, Mark, for the really interesting analysis.
I have always thought that the reasoning that each school should try to anticipate Ofqual’s grade distribution for it then allocate CAGs as close to it as possible, weird and wrong. If someone might ask you do something that’s wrong, you shouldn’t try to comply as much as possible. If you don’t pre-comply and they ask and force it on you, then so be it, and the wrong is their fault, but you shouldn’t pre-comply of your own initiative, which makes it your fault.
But maybe schools didn’t understand, or they forgot how the standardisation was going to work. One school leader told me of the fear that if they submit more high grades than the expected numbers, “everyone might be downgraded”. That fear sounds to me like a confusion between how this year’s downgrading was going to work (the students lowest in the rank order would be downgraded) and how downgrading of non exam assessments works (a downgrade percentage is applied to the score of every student in the cohort).
I think schools didn’t have a clear head on this. Another school leader told me that he really thought that Ofqual’s process was going to work.
Reply
Dennis Sherwood says:
…as these comments – all most thoughtful and insightful, thank you, everyone – make so clear, this year’s process has been an almighty muddle.
Standing back a moment, if I may, I wonder if a fundamental reason that everything has gone so wrong is the fact that, totally inadvertently I’m sure, Ofqual created two total populations of the ‘right’ grades: the machine’s and the CAGs? Why are they different? Which one is ‘right’?
For the first time ever, every candidate has a ‘second opinion’ – Ofqual’s nightmare, as verified by their decision in 2016 to make it harder to appeal, so suppressing the discovery of this comparison (https://www.hepi.ac.uk/2020/08/08/weekend-reading-something-important-is-missing-from-ofquals-2020-21-corporate-plan/).
But that’s only one part of the muddle. Not only are there two other comparators – UCAS predictions and mocks – but the CAGs themselves were compiled in different ways at different schools.
I am increasingly convinced that the fundamental blame for all this is Ofqual’s. They did not specify the process, they did not define the rules, they created absolute havoc.
And, even worse, because the key document is entitled “Guidance” (https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/908368/Summer_2020_grades_for_GCSE_AS_and_A_level_110820.pdf), they will, I am sure, slide past any responsibility for what any school actually did: “We offered ‘guidance’ only; schools were allowed to do what they thought best”.
Those, like ASCL, who know the ‘system’ well, realised that a hard “no grade inflation” policy underpinned everything. And they were right. That’s exactly what happened on A level results day. In anticipation of that, they advised their schools accordingly – and I, personally, lay no blame on them for doing so. I think they acted honourably, as did the schools that followed their advice – as indeed did those who acted on FFT Education Datalab’s analyses of their draft submissions.
The tragedy is heightened by the fact that those who ‘won’ are exactly those who did not follow that advice – and they only ‘won’ because of another Ofqual failure: the failure to ‘sense-check’ the submissions and to distinguish between the ‘plausible’ and the ‘implausible’ (https://www.hepi.ac.uk/2020/08/12/the-great-cag-car-crash-what-went-wrong/).
And there’s another Greek tragedy as regards what schools actually did to determine CAGs and rankings. I don’t know what they actually did; I wasn’t around the table. But I would bet my hat that many schools wished to be as conscientious as they could possibly be – subject to one thing: how they could demonstrate, after the event, that they had been ‘fair’, and could defend themselves against the law suit from that stroppy parent?
So here’s the irony. Because of that fear, schools were forced back into an algorithm – an algorithm of their own making, an algorithm with an audit trail, an algorithm which they would be able, if challenged, to prove that they followed in the same way for every student.
An algorithm that takes [this homework mark], weighted by [this percentage]; [that test result] weighted by [that percentage]; an algorithm that must, must, must exclude any subjective, unprovable ‘feelings’ like ‘this student [tried really hard in class]/[is shy]/[doesn’t get support at home]’ – all the things that really count. All the things that really matter. All the things that should have been in that “holistic judgement”, but were excluded because they could not be ‘proved’.
Oh dear oh dear oh dear.
Why oh why oh why can teachers not be trusted? And how can teachers who really can’t be trusted held to account?
There is so much ‘collateral damage’ caused by all this.
But that damage isn’t ‘collateral’.
It is to ‘me’, ‘my son’ or ‘my daughter’.
How can we truly build a better world?
Reply
Dennis Sherwood says:
…and of course – and I should have just said this – the policy of “no grade inflation” itself is pernicious, and the way it was attempted to be enforced this year – by subject within school, and with no opportunity to submit and explain outliers – even more so.
…typo alert too! – “And how teachers who really can’t be trusted be held to account?” of course. Sorry, again!
Reply
Dennis Sherwood says:
…if not a typo typo alert… I must be getting tired…
And how can teachers who really can’t be trusted be held to account?”
Reply
Mark says:
Hi Huy,
It is very confusing retrospectively so I can only imagine how it must have felt in the heart of lockdown when schools were attempting to make sense of things. I think the FFT algorithm offer in May must seemed very tempting for over 2400 Aspire-linked schools to submit their GSCE CAGs. And the results they got back would have given them a easy-to-implement “solution” to the challenge of ensuring grades were in line with cohort Prior Performance and Historic data. So those schools would have probably felt they got it “right” by the time final CAGs were submitted – even if that meant some students they had passed subsequently failed. The issue was that a large number of other settings had no contact with FFT, no idea how to implement the ASCL step-by-step and just muddled on in their own way, believing OFQUAL’s standardisation would sort it out. The CAG reversal – at least for GCSEs – had the completely opposite effect for both of these types of schools. The do-it-right settings suddenly found that their self-administered (with the help of FFT and ASCL) standardisations left their cohorts penalised by moderation that hadn’t been applied at any point to the “muddlers” whose students benefitted from the “wildly optimistic” (sic) raw CAGs their centres submitted. I know my son’s school was in the former category as his CAGs and his standardised OFQUAL grades were exactly the same across 10 GCSEs (And the schools 8-stage assessment model was word for word the same as ASCLs!) What I find harder to accept, however is that many students who were predicted to pass by the teachers that know them best, were needlessly sacrificed by the system from OFQUAL downwards, in the pursuit of comparable outcomes – an objective baked into the process throughout but ultimately worthless due to a lack of insight planning and rigour from those responsible for overseeing the endeavour.
Reply
Mark says:
Dennis, I think if students could access the original CSV-file data with the “raw” CAG grades that centres submitted to FFT for their statistical moderation, via a SAR, a truer picture would begin to emerge of the holistic assessments they were promised back in April. And it should have been these un-moderated teacher-based CAGs that Aspire-linked schools were told to re-submit to OFQUAL and exam boards when it became clear that post-submission moderation was off the table. You either listen to the teachers who know their students best across the board, or you don’t. There’s no half and half.
Reply
Dennis Sherwood says:
Hi everyone – there’s an article by Geoff Barton on Schools Week – https://schoolsweek.co.uk/ascl-writes-to-ofqual-over-deflated-grades-fears/ – in which he is advocating that schools who ‘internally moderated’ students downwards as a result of feeling constrained by the rationing of grades should be allowed to appeal. Which is good news, and will help some students who have been penalised.
The article ends with a statement from an ‘Ofqual spokesman’ in essence blaming teachers. Despicable.
Reply
Keda Richens says:
Good news and also yes, despicable!
I feel so sorry for the teachers caught up in this. We have had to send quite a lot of emails to the college and Ofqual and worry now that it has put my daughter’s poor teacher in an even worse position as she said the centre downgraded her award. As my daughter put it ‘we don’t want to bait her out’. It was not her fault at all.
It’s so awful.
Reply
Dennis Sherwood says:
Good, yes, but followed by this announcement from Ofqual, confirming the status quo: https://www.gov.uk/government/publications/summary-guidance-on-appeals-for-gcse-as-and-a-level-summer-2020/summary-guidance-on-appeals-malpractice-and-maladministration-complaints-for-gcse-as-and-a-level-grades-in-england.
That is bad news, but not surprising news – what else would they say?
Recent history, though, is about U-turns, U-turns resulting from continued public pressure. So we need to keep the heat turned up – speaking to journalists, making a fuss, lobbying the Education Select Committee.
Next Wednesday, 2 September, the Select Committee is due to meet whomever might be left to represent Ofqual. There is still time to make a submission…
https://committees.parliament.uk/call-for-evidence/97/the-impact-of-covid19-on-education-and-childrens-services/
Reply
Keda Richens says:
OOoof.
Thank you for the links. I’ve shared them as widely as I can.
Reply
Mark says:
Dennis,
In my view, the OFQUAL statement is a bluff, written to confuse and confound appellants. The relevant section is the one that says “A school or college cannot raise concerns about its CAGs […] because the national process of standardisation did not operate as expected. Instead, the school or college would need to provide evidence of the original approach that it took and show why this was not appropriate, given the published guidance.”
OFQUAL are in no position to make the first assertion since they DID stipulate that the national process of standardisation would take place in the original guidance for a clear reason “We will do this to align the judgements across centres, so that, as far as possible, your students are
not unfairly advantaged or disadvantaged this summer.” (from the original guidelines, now withdrawn) Centres who applied local cohort pre-standardisation – via the FFT GCSE Statistical Subject Moderation or the ASCL step-by-step were acting in good faith with the guidelines in force at the time. Many of these would have applied stage Seven standardisation (from the ASCL step-by-step, “Stage 7: Moderation of grades by SLT using national indicators and understanding of past school performance at subject level”) to make their grades OFQUAL Standardisation-ready. But when national standardisation was killed off, pre-standardised CAGs became “wrong” data in that instant, as they had the standardisation metric built in. OFQUAL essentially broke its own original guidelines by withdrawing the national process of standardisation which removed the possibility for alignment of judgement across centres and in doing so allowed an unfair advantage to certain centres over others. In the circumstances the FAIREST thing to do would be to allow centres that can PROVE their CAGs had been affected by pre-standardisation to reinstate the original grades. Thankfully the FFT GCSE Statistical Subject Moderation required schools to upload a CSV of their cohort with “raw” CAGs for every subject. It would therefore be relatively easy to re-issue those CAGs once they had been verified. I can’t really see what else they can do to prevent both discrimination and malpractice claims flying into them from the 50% of state schools who took the pre-standardisation route. Just to re-iterate, the reports that schools got back from FFT would have reflected the adjustment necessary to bring the “raw” CAGs back in line with historic data. When they say “Looked at another way, were these proposed grades to be confirmed, the share of pupils awarded a grade 4 or above would increase from 71.4% to 80.8% in English language, from 73.7% to 79.0% in English literature, and from 72.5% to 77.6% in maths.” This equally represents the negative adjustment their reports would have “suggested” that SLTs made to their CAGs to bring them in line with a national standardisation that never happened. How many borderline students – considered holistically by teachers that know them best – went into pre-standardisation with a well-earned pass were failed in pursuit of comparable outcomes that were themselves ultimately discarded? As ever, the forgotten third are the true victims of OFQUAL’s hubris.
Reply
Mark says:
It could also be argued that the OFQUAL pledge in its 17th August u-turn, permits schools to differentiate their “raw” CAGs from their “moderated” ones and therefore request that the higher “raw” CAG is upheld. The relevant sentence is “We have therefore decided that students be awarded their centre assessment for this summer – that is, the grade their school or college estimated was the grade they would most likely have achieved in their exam – or the moderated grade, whichever is higher.” Centres would only need to prove the existence of two sets of grades – unmoderated and moderated – to select the higher. Moderation and standardisation is a action that could have happened at any stage of the process, not just at the end. The proof point is demonstrating there was a grade difference effected by moderation at some point in the process.
Reply
Dennis Sherwood says:
Mark – great stuff, thank you: have you put this in a submission to the Select Committee? I’m sure it would be very helpful to them; it also places these views in the public domain on a very visible and influential platform.
Reply
Mark says:
Hi Dennis,
Thanks. I had a quick look at the submissions criteria and will put something together tomorrow.
Did you see the full letter from Geoff Barton? Its on the ASCL site here:
https://www.ascl.org.uk/ASCL/media/ASCL/News/Newsletters/Letter-to-Sally-Collier-Ofqual-24-August-2020.pdf
I was surprised he didn’t make more of the “forgotten third” angle in his letter (a definite political hot potato for the regulator) given the headline downgrades that a pre-standardisation exercise would have delivered at grade 4. As the man himself once said “Why do we insist in rubbing their noses in disappointment?” – especially after the year they have had so far.
Reply
Dennis Sherwood says:
Thank you Mark – and I certainly agree with you about the “forgotten third”.
I do hope that the Select Committee hearing next Wednesday does not get bogged down digging deep holes into ‘interesting’, but none the less distracting, details, but manages to penetrate to the fundamental issues, which to me are:
1. Who, specifically, took the decision to design and build a ‘predictive forecaster’ rather than a ‘sense-checker’?
2. When was this decision taken?
3. What other approaches were suggested, and why were they rejected?
4. Who, specifically, designed the algorithm, and wrote the corresponding computer code?
5. Why were schools asked for CAGs, when they were known, from the outset, to be superfluous?
6. Given that schools were asked for CAGs, why were they denied the opportunity, at the same time, to provide evidence for outliers? (https://www.hepi.ac.uk/2020/04/18/weekend-reading-this-years-school-grades-ofquals-consultation/)
7. Why were Ofqual’s ‘Guidelines’ not clearer, more specific, and more honest about what was actually happening?
7. Given where we are now, should schools who followed the implied rule of “no grade inflation” – a rule that the A-level grades as actually awarded prove was applied – be allowed to appeal CAGs that were “internally moderated” downwards, against the teachers’ better judgement?
8. Looking ahead to the return of exams, would Ofqual explain what, precisely, what is meant by their statement of 11 August 2019 that “…more than one grade could well be a legitimate reflection of a candidate’s performance…”? What are the implications? (https://www.gov.uk/government/news/response-to-sunday-times-story-about-a-level-grades)
9. Given that “This is not new, the issue has existed as long as qualifications have been marked and graded” (same source), why has the problem of unreliable grades not been long since resolved? [And don’t get side-tracked by spurious excuses about ‘marking errors’ – this is about the policy for grading.]
10. What actions will Ofqual now take to resolve the 1-grade-in-4 is wrong problem, so ensuring that all grades are reliable and trustworthy, in compliance with Ofqual’s statutory obligation under Section 22 of the Education Act 2011?
Other suggestions please!!!
Reply
Mark says:
I would add to that list that, given their Goal 1 is “Regulate for the validity and safe delivery of general qualifications” How do they propose to deal with the moral hazard they have created in allowing those that took the greatest risk with over-inflated CAGs to reap the greatest benefit? Blaming schools for diligently applying a moderation that OFQUAL themselves had proposed after dropping that moderation with no audit of the underlying source data for the CAGs that remained unstandardised is borderline malpractice.
Reply
simon kaufman says:
Dennis, we can only hope that members of the select committee will on Wednesday take your ‘ten questions’ above as a blueprint around which to structure their questioning of ministers and DFE/Ofqual representatives and simply repeat these questions when met with obfuscation or refusal to engage with the substance of your questions.
Perhaps also the select committee may be able to bring greater public attention to the TAG/CAG issue highlighted through your blog and the issue of the prejudicial and discriminatory treatment of students at schools and colleges who in good faith used either the ASCL or FFT tools to attempt to replicate the outcomes of Ofqual moderation; from contributions to your blog discussion it is now clearly evident that those schools and colleges which did not attempt this process have ‘won out’ in this year’s process for their students whereas those schools and colleges who stuck as closely as possible to the Ofqual rubric supported by well-intentioned ASCL/FFA modelling tools have lost out for their students to the detriment of their life chances whether in terms of university places or progression from gcse to 16+ choices matching their aspirations – this is neither fair nor in accord with the stated goals of government policy.
The refusal either to allow appeals on a whole school/college cohort or individual student/subject cohort basis is wholly unreasonable ( particularly as this in effect denies these students access to the university choices they would potentially have secured had their school/college submitted unmoderated TAGs following the u-turn over CAGs and which may well have an access dimension to it – was it state schools, sixth form colleges and FECs who made greatest use of the ASCL modelling tool?) and warrants far greater exposure in press and broadcasting coverage. There is a real risk that Wednesday’s hearing at the select committee will focus on the position and retention in office of Williamson and Gibbs rather than the process issues of substance highlighted within these blog discussions. As Ofqual – according to one contributor above – is already in possession of CSV files of raw tag data from the ASCL/FFA exercise surely it is a simple step – at least operationally – to process this raw data to identify outliers disadvantaged by the flawed standardisation process and to upgrade accordingly in individual instances (‘biting the bullet’ on yet further consequences for HE would be a necessary and uncomfortable by-product but would reflect principles of natural justice).
On Wednesday and in the weeks ahead there also needs to be a focus on what happens in summer 2021; alternative scenarios for Plan B need to be modelled and publicly scrutinised now given that the ability of schools and colleges to deliver anything like the full AL curriculum including the material not covered during the lockdown must be seriously questioned and with any model requiring algorithmic standardisation looking untenable (politically even were it to be shown by independent statistical experts to be sustainable).
Is there an alternative to TAGs reinforced by examples of assessed work which could be subject to some form of moderation? This would require a serious stepping back from high stakes formal examinations and also an overcoming of ministerial obsessive suspicion of anything other than the most traditional form of examination but could be the beginnings of a restoration of trust in the judgment of educationalists and just perhaps in the longer term of an opening up of discussion about our 14 – 19+ curriculum model (perhaps resulting in the demise of GCSE as a high stakes 16+ examination and a recognition that, at most, this is only an intermediate stage in a continuum informing such specialisation as is necessary post 16+ to inform future FHE and other career progression choices).
Reply
Dennis Sherwood says:
Simon, thank you; much appreciated…
And there are a few ideas around now for what might happen next – have you seen this https://www.tes.com/news/halfon-no-algorithm-if-second-wave-hits-exams-2021 from Robert Halfon? And this one, which is a bit more radical – https://www.tes.com/news/how-avoid-exams-fiasco-trust-teachers…
Reply
Add comment